Your prospect just finished their sentence. The line goes quiet. One beat. Two.
And you've lost them.
Not because your offer is weak. Not because your script is wrong. Because your voice agent took a second too long to respond, and a second in a conversation feels like a lifetime.
Picking the best LLM for voice agents is less about which model wins benchmarks and more about which one holds the pause between turns. That pause is where your model lives.
Human turn-taking gaps run from 0 to 300 milliseconds across 10 languages, with a cross-linguistic median around 100ms (Stivers et al, PNAS 2009). That's the pause between "how are you?" and "good thanks." Your ear has been tuning itself to that rhythm since you could speak.
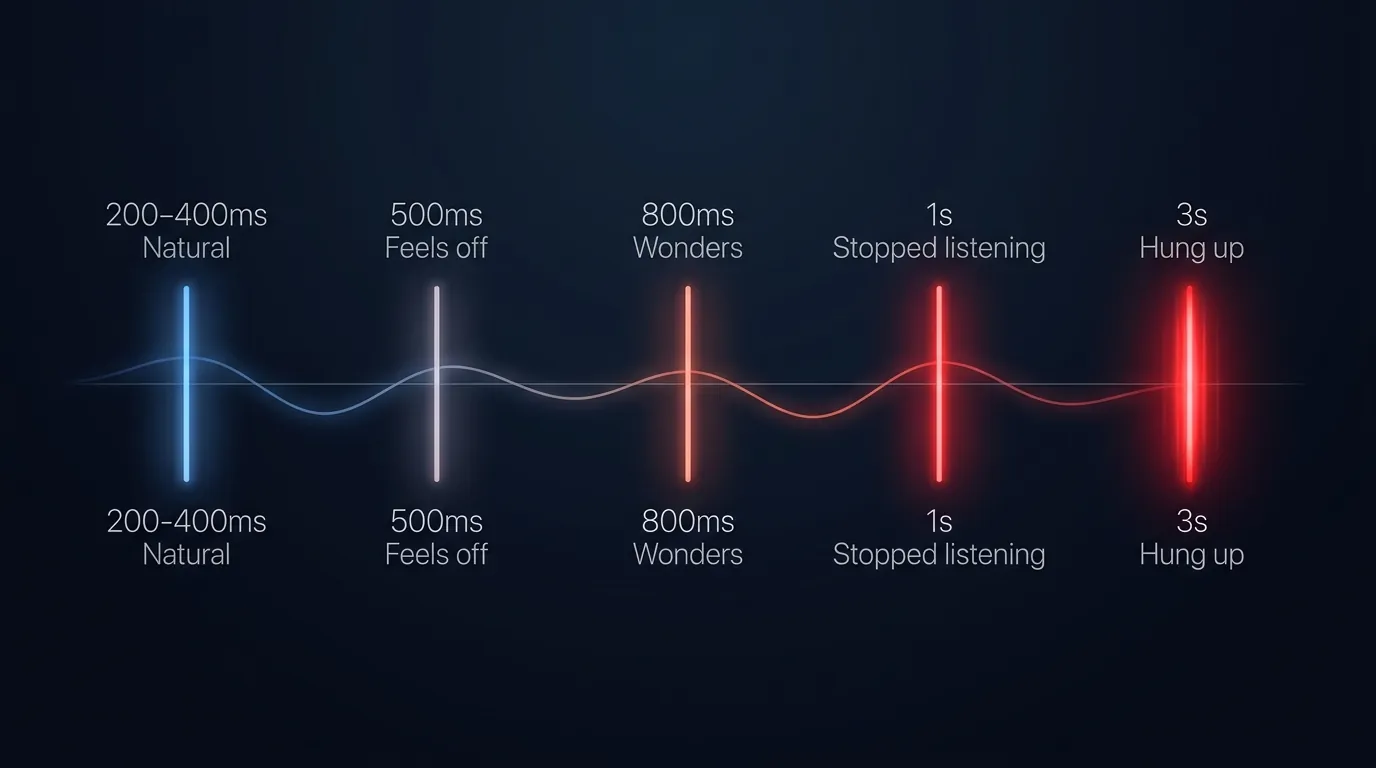
For voice agents, anything under 500ms still feels natural. Past 800ms the wheels start coming off. Past one second and the caller has stopped listening. Past three seconds, they've hung up.
The LLM you pick is the thing that lives in that gap. On every turn. Not just the opening line. Every turn your agent has to respond.
Pick wrong and your entire sales funnel leaks out of the silence.
If your agent already sounds slow, the model is usually not the first thing to blame. We wrote a full teardown on where the invisible latency actually hides: Your AI agent sounds slow. The AI isn't the problem. Read that first if you haven't.
Where does voice agent latency actually hide?
Voice agent latency hides in the middle turns, not the opening line. Most demos test the "hi, this is Jess calling from..." bit, which is easy. You can precompute it. You can stream it. Opening latency is a solved problem.
The hard one is the middle. The turns where your caller asks a question, your agent has to look up context, pull a knowledge base entry, match an intent, and respond.
Every one of those turns is a fresh race against the 800ms threshold. That's where models diverge. That's where your choice shows up. We wrote a full teardown on how we tuned our stack to hold sub 800ms end to end if you want the engineering detail.
What is the best LLM for voice agents by job type?
Every major model has a real edge and a real gap. Pick the one whose edge matches your job.
Quick scan first, then the detail below.
| Model | Speed | Reasoning | Instructions | Best for |
|---|---|---|---|---|
| GPT-4o | ️ | ️ | Emotional calls, retention, complaints | |
| GPT-4.1-mini | ️ | Default cold call, booking, qualification | ||
| GPT-4.1 standard | ️ | Long layered calls, branching discovery | ||
| GPT-4.1-nano | Scripted front door, routing, FAQ | |||
| GPT-5 | Legal, medical, technical triage | |||
| Claude Haiku 4.5 | ️ | Compliance heavy, rule dense, regulated | ||
| Claude Sonnet 4.6 | ️ | Premium concierge, warm retention | ||
| Gemini 3 Flash | ️ | ️ | Multilingual, multimodal, document heavy |
strong, ️ workable with trade-offs, avoid for this. Detail on each model below.
GPT-4o
Reads tone and emotion better than the 4.1 family, which matters when the call is hot. First token latency sits mid-pack and integration support is everywhere.
The downside: instruction following lags the 4.1 family, so it'll hedge or add disclaimers your script never asked for. Pricing is mid-tier.
Best for: complaints handling, grief support intakes, and any retention call where tone outweighs structure.
GPT-4.1-mini
Fast first token and tight instruction following, cheap enough to run at volume without flinching. See OpenAI's model reference for current pricing and context window.
Long system prompts (over roughly 8k tokens) start to degrade it, and heavy RAG or knowledge base lookups expose shallow reasoning. Off-script turns will throw it if the prompt is loose.
Best for: cold calls, lead qualification, appointment booking. Anything structured where the prompt is well-scoped. We run it on arrears chase campaigns at 200 calls a day per site, and on dental clinic intake for after-hours bookings.
GPT-4.1 standard
Best instruction following in the OpenAI family, holds long context (1M window) without drifting, and stays sharp across layered conversations.
Higher latency than mini and you will feel it on quick turns. More expensive per call, overkill for anything simple and scripted.
Best for: financial planning discovery, clinical triage, or B2B demos where the caller jumps between five objections in three minutes.
GPT-4.1-nano
Lowest latency in the OpenAI family at the cheapest per-token rate. Brilliant at classification and routing.
Breaks on anything ambiguous. Weak at multi-step reasoning, with a small context window that limits knowledge-base use.
Best for: appointment confirmations, delivery reschedules, intent routing, and basic FAQ flows your script fully controls.
GPT-5
Deepest reasoning on the market, holding complex logic chains under real pressure. Best in class on edge cases nobody trained it on.
Noticeably slower first token, which you will feel every turn. Pricing is high enough to rethink your unit economics, and it is overkill for the 95% of voice agent jobs that don't need it.
Best for: enterprise technical pre-sales, legal intake triage, and medical symptom triage. Anywhere wrong reasoning costs serious money.
Claude Haiku 4.5
Follows long system prompts more literally than most models and stays calm across long conversations. Cleanly refuses requests outside its scope, which is gold for compliance work. Anthropic's model reference has the benchmarks.
First token latency sits slightly behind GPT-4.1-mini. Fewer plug-and-play integrations on voice platforms, and tool calling is still catching up.
Best for: compliance-heavy intake and agents with 30+ rules. Long conversations where drift would burn you. Hospitality scripts that quote NZ Privacy Act, healthcare front desks, and financial advice intake (we've written on why dumb voice platforms destroy your brand if regulation is your world).
Claude Sonnet 4.6
Warmest natural voice of any model and reads less like a script. Strong on nuanced reasoning while holding structure.
Slower than mini and you will feel it on quick turns. Higher cost per call, and it occasionally over-explains when you want a short answer.
Best for: premium concierge bots and high-ticket sales follow-ups. Retention calls where the caller needs to feel heard rather than processed.
Gemini 3 Flash
Multimodal handling is its strong suit, with images, documents, and mid-call switches handled cleanly. Multilingual support beats every other major model. First token sits competitive at the price (cheaper than mini after the 3 Flash launch in April 2026).
Instruction following on structured flows runs loose, getting creative when you need literal. Tool calling has improved with the 3 Flash release but still lags OpenAI and Anthropic for production-grade voice.
Best for: multilingual customer service across markets like Auckland, Sydney, and the Pacific. Document-handling agents (a customer uploads a contract mid-call). Travel and hospitality bookings where creative phrasing is a feature.
How do I pick the right LLM for my voice agent?
Three questions. Answer them and the model picks itself.
One. How tight is your script?
Loose and emotional? Lean 4o or Sonnet 4.6. Tight and transactional? Lean mini or nano. Long and branching? Lean 4.1 standard or Haiku 4.5.
Two. How big is your system prompt and knowledge base?
Small (under 4k tokens)? Anything works. Medium (4-16k)? Mini or Haiku 4.5. Large (16k+) or heavy RAG? You want 4.1 standard or Haiku 4.5.
Three. How expensive is a wrong answer?
Cheap (your caller just asks again)? Any of them. Expensive (hangup or compliance fire)? GPT-5 or Sonnet 4.6. Catastrophic (legal, medical, financial)? GPT-5.
That's your decision tree. Benchmarks do not take phone calls.
Why does your LLM choice decide every voice agent call?
Your model choice shows up in every pause of every call you run.
Miss the sub-500ms window and you sound like a bot. Push past 800ms and the caller starts checking out, past a second and they're gone.
Your offer, your script, your list, your team. None of it matters if the agent cannot hold a natural conversational beat.
The right model is the one that holds the beat for your job. The loudest model on the leaderboard rarely is.
Want to hear a properly picked model on a live call?
See the stack in action on our AI voice agents page, or book a live demo and hear it answer your own questions.
Frequently Asked Questions
What's the best overall LLM for voice agents in 2026?
There's no single "best" model. The right pick depends on the job the agent is actually doing.
For a tight outbound cold call script, GPT-4.1-mini is the default. Compliance-heavy intake with 30+ rules sits with Claude Haiku 4.5. Emotionally loaded calls (retention, grief support) belong with GPT-4o or Claude Sonnet 4.6.
Pick on the job. Whichever model that ends up being.
What is a normal response latency for a voice agent?
Human conversation gaps run from 0 to 300 milliseconds across 10 languages, with a cross-linguistic median around 100ms (PNAS 2009).
For voice agents, anything under 500ms feels natural. Between 500ms and 800ms is workable for complex queries but starts to feel slightly off. Past 800ms the caller perceives awkward silence, and past one second the delay feels like a system problem. Past three seconds most callers hang up.
Why is GPT-4.1-mini not always the right default?
GPT-4.1-mini is a great default for well-scoped outbound calls, but it degrades on long system prompts (over ~8k tokens), struggles with heavy RAG or knowledge base lookups, and breaks on off-script turns. If your agent has a long prompt, a big knowledge base, or a caller who can improvise, you want GPT-4.1 standard or Claude Haiku 4.5 instead.
When should I use GPT-5 for a voice agent?
GPT-5 is the right pick only when the call's value per minute justifies the extra latency and cost. Good fits: enterprise technical pre-sales, legal intake triage, medical symptom triage, or any call where the wrong reasoning costs serious money. For 95% of voice agents, it's overkill.
Is Claude Haiku 4.5 good for voice agents?
Yes, particularly for instruction dense flows. Haiku 4.5 follows long system prompts more literally than most models, stays calm on long conversations, and cleanly refuses out of scope requests. The trade off is slightly slower first token latency than GPT-4.1-mini and fewer plug and play integrations on voice platforms. For compliance heavy and regulated industries, it's often the right pick.
What's the catch with Gemini 3 Flash for voice?
Gemini 3 Flash is genuinely fast and has the best multimodal and multilingual handling of any major model. The catch is instruction following on structured flows. Gemini gets creative when you need literal, which is great for travel booking but bad for compliance intake or lead qualification that must collect specific fields.
Leonardo Garcia-Curtis
Founder & CEO at Waboom AI. Building voice AI agents that convert.
Ready to Build Your AI Voice Agent?
Let's discuss how Waboom AI can help automate your customer conversations.
Book a Free Demo