
7 min read · Operator perspective · Last updated 7 May 2026
Watching a Sunday afternoon YouTube tutorial, you can wire up basic DIY voice agents in 10 minutes. Microphone in. Speech to text, into an LLM, into text to speech.
Twiddle a system prompt. Make a call. It works.
Then you give it to a real customer and the bottom falls out.
We've shipped voice agents into property, mortgage broking, dental, hospitality and inbound government compliance work across NZ and AU. Same pattern, regardless of your industry. The build is the easy part. The 90 days after launch is where most DIY voice agents quietly get parked.
Here's why companies that don't do this for a living (yours included, if you start now) can't get past the wall.
In this article (everything you need before you build your own)
- 1. Why does the 10-minute build become a 90-day project?
- 2. Why are humans the wrong benchmark for AI voice?
- 3. What does a production voice agent stack actually look like?
- 4. Why does voice quality matter more than the LLM?
- 5. Which LLM is right for a voice agent?
- 6. Why does a voice agent need a weekly review loop?
- 7. What now for DIY voice agents?
- 8. Frequently asked questions
The Setup
Why does the 10-minute build become a 90-day project?
The YouTube tutorials aren't lying. The basic plumbing of a voice agent really is 10 minutes of work. The 90 days come from everything that isn't in the tutorial: orchestration, voice tuning, weekly review, and a feedback loop. None of that fits in a 10-minute clip.
What does the YouTube demo skip?
The demo doesn't show the caller from Whangārei pronouncing a suburb the model has never heard. It doesn't show what happens when someone interrupts mid-sentence. It doesn't show the call where the LLM hallucinated a price that doesn't exist.
When does the agent break in front of a paying customer?
Around call 47. Some compounding edge case finally trips the agent in a way the demo never surfaced. By then a real prospect has heard it.
10 minutes to build, 90 days to ship
The ratio every DIY voice agent project hits. The build is the cheap end of the work. Everything that makes the agent safe to put in front of paying customers sits in the 90 day tail.
The Human Bar
Why are humans the wrong benchmark for AI voice?
Humans aren't wrong as a benchmark in the abstract. The problem is callers don't grade humans and AI on the same scale.
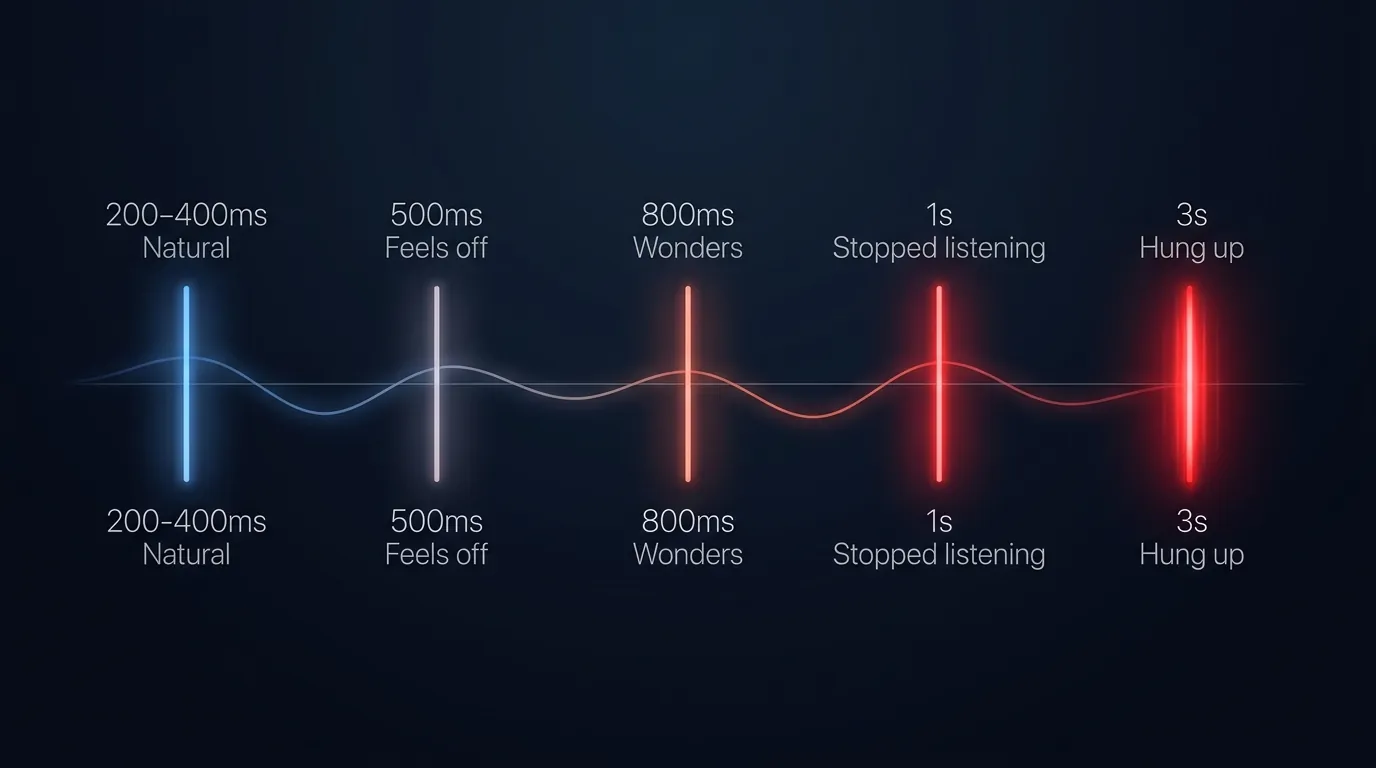
A human SDR fumbles a word and you forgive them. Your AI agent does the same and the call is often over before recovery. The bar your callers expect is closer to 98% than 80%.

How much does one fumble cost?
We measured this on a 6,000-call campaign for a Tauranga mortgage adviser. The agent that interrupted the caller even once in the first 8 seconds had a 17% drop-off.
The tuned version, where we'd silenced the early-step-in behaviour, held them through the qualifying questions. Same model, different listening behaviour. (NN/g has the broader UX research on this.)
What's the real bar?
95% sounds great in slide decks. On the phone, 95% gets hung up on. Aim for 98% before you ship.
98%, not 80%
The real bar callers grade your voice agent against. They've spent a lifetime listening to humans on the phone. The dial doesn't move when the talker swaps to AI.
Orchestration
What does a production voice agent stack actually look like?
A production voice agent looks more like an orchestra than a soloist. A router picks the right sub-prompt for what your caller actually wants. A tool layer handles bookings, payments and CRM lookups.
Guardrail and recovery prompts catch off-script detours. A closing prompt fires the right CRM tag. One mega-prompt would hallucinate through three of those.
How does production split the call paths?
Take a Sydney commercial cleaning client we built for. The agent runs 9 distinct call paths from one inbound number. Quote requests.
Complaint triage. Recurring service changes. Out-of-area refusals. Each path is its own configured node with its own data shape.
What happens with one mega-prompt?
Try a single mega-prompt across all 9 paths. It'll hallucinate through three of them. The caller hears the rest. Demo to production isn't a config tweak. It's an orchestration rebuild.
| What you ship | Demo | Production |
|---|---|---|
| Prompt | One mega-prompt | Router + 5 to 9 sub-prompts |
| Tools | None or a placeholder | Real CRM, calendar, telephony |
| Guardrails | Hope | Off-topic interceptor + recovery |
| Closing | "Goodbye" | Tag, transfer, schedule, confirm |
| Test set | ~5 happy-path calls | 200+ simulated, then 1,000 live |
Skip the 90 day tail.
We ship production-ready voice agents in 2 to 4 weeks for focused use cases. Orchestration, voice tuning and the weekly review loop are already running.
Voice Quality
Why does voice quality matter more than the LLM?
The voice you pick is the whole product because the first 4 seconds of every call ride on it. A great voice covers the rough edges of an average prompt.
A wrong voice tanks a brilliant one. Most DIY rollouts pick a voice off the demo shelf and never test it on local content. The cleverest LLM in the world doesn't get heard if the caller is gone in 4 seconds.
What are the three voice traps?
1. You pick the most natural-sounding English voice in the demo and never test it locally. It mispronounces "Whangārei", "Glenelg" or your brand name on every call.
2. You ship a voice with the wrong age, gender or warmth for the audience. A 60-year-old buyer hears a chirpy 25-year-old voice and feels sold to.
3. You don't test the voice with the LLM's actual phrasing. Voice and model have to be co-tuned because the model writes the words the voice has to read.
Does the voice swap really move the numbers?
We swapped voices on an Auckland property management agent. Voicemail callback rate moved from 11% to 23%. Same script, same call windows, different vocal register. More on local persona work in how to localise a voice agent for NZ accents.
Model Choice
Which LLM is right for a voice agent?
There's no single best LLM for voice. Routing and tool calls need a fast model with first-token latency under 800ms.
Nuanced reasoning needs a heavier model that handles a curveball gracefully. Transcription needs a model that won't mishear "Hawkes Bay" once in 100 calls. Pick one model for all three jobs and every call feels like a compromise.
What's the latency rule?
The 800ms-or-better first-token band is what makes a voice agent feel alive instead of clunky. Past 1.4 seconds and the caller starts checking if the line dropped. (Google Duplex's 2018 work set the benchmark.
800ms first-token, or callers leave
The latency band that separates "feels alive" from "feels broken". Past 1.4 seconds you've lost the room. Pick a fast routing model just for this reason.
Do you really need three different models?
Most DIY builds pick one model and force it to do all three jobs. Then you wonder why every call feels like a compromise. We covered the model selection logic in detail in the best LLM for voice agents on sales cold calls.
Feedback Loop
Why does a voice agent need a weekly review loop?
Your voice agent is not set and forget. Every real call is a data point: questions you didn't anticipate, off-script detours, phrasing the agent fumbles, bookings that almost happened.
Without weekly review, the agent that worked in March is mediocre by June. Production agents get better. DIY agents quietly decay.
What does a real review loop look like?
Our portal logs every call against a tagging schema, scores transcript quality automatically, and surfaces the 5% of weird calls that need human eyes. The team works through them on a Friday rhythm.
Why does call 5,000 outperform call 500?
Because every call between has been tagged, reviewed and fed back into the prompt your agent runs on. New objections feed the recovery flow.
Mispronounced names go into a pronunciation dictionary. Phrasing that flopped gets rewritten. We wrote about how the loop runs every night in AI voice agents get smarter every night.
5,000 vs 500
The agent on call 5,000 isn't the same agent as call 500. Every flop has been tagged, every edge case fed back, every bad voicemail rewritten. That delta is the work most DIY teams stop doing on day 30.
The Take
What now for DIY voice agents?
If you've watched a YouTube video and thought "we could build this in-house", you're not wrong about the build. You're underestimating everything that comes after.
DIY voice agents are easy to start and unforgiving to ship. They live or die on five things. How high the human bar sits.
How the orchestration is structured. How the voice is chosen. Which model does which job. Whether someone is paying attention to the calls every week.
We do this for a living. That's the only honest reason to pick a partner over a weekend project you'll regret in 90 days.
Want a working voice agent without the 90 day tail?
We ship production-ready voice agents in 2 to 4 weeks for focused use cases, with the orchestration, voice tuning and weekly review loop already running.
Frequently Asked Questions
Can a small business build DIY voice agents with off-the-shelf tools?
For very simple use cases like FAQ playback or after-hours messages, yes. For anything that books, qualifies, transfers calls or touches a CRM, the orchestration, voice tuning and ongoing maintenance is what kills the project. Most DIY builds we see are working in 10 days and abandoned in 90.
How much testing should a production voice agent go through before launch?
Minimum 200 to 300 simulated calls covering the happy path, off-script detours, accent variations, interruptions and edge cases. Then a controlled live trial of 500 to 1,000 real calls before going wide. Anything less and you're using your customers as the test set.
What's the most common reason DIY voice agents fail?
Voice quality and orchestration tied for first. Either the voice sounds wrong for the audience and callers churn in the first 4 seconds. Or the agent's been built as one mega-prompt that falls over the moment a caller goes off-script. Both are fixable with experience.
How long does Waboom AI take to ship a production voice agent?
Days, not weeks, for a focused use case. Inbound qualifier. Outbound lead follow-up.
Appointment booking. Two to three weeks for multi-path orchestration or complex CRM integration. Every agent goes through a weekly review cycle for the first three months. That's where the agent actually gets good.
Why does the agent on call 5,000 outperform the agent on call 500?
Because every call between has been tagged, reviewed and fed back into the prompt and tools. New objections get added to the recovery flow.
Mispronounced names go into a pronunciation dictionary. Phrasing that flopped gets rewritten. Without that loop, your agent quietly drifts.
Is voice quality really more important than the LLM?
Inside the first 4 seconds of a call, yes. Without question. The caller decides whether to stay based on how the voice sounds, the pace, the warmth, the accent fit. The cleverest LLM in the world doesn't get to demonstrate intelligence if your caller has already hung up.
Leonardo Garcia-Curtis
Founder & CEO at Waboom AI. Building voice AI agents that convert.
Ready to Build Your AI Voice Agent?
Let's discuss how Waboom AI can help automate your customer conversations.
Book a Free Demo

