In February 2026, ElevenLabs shipped v3 to general availability. They called it the most emotionally expressive AI voice model on the market. In the same documentation, they told developers not to use it for real-time voice agents.
That tension is the whole story.
v3 is the rendering engine. Flash v2.5 is the call-floor engine. Both run the same voices, so you keep your chosen voice and just pick the engine that fits the job.
Here is when each one wins, with the numbers, and the catches the launch coverage glossed over.
Latency
The 800ms cliff
Live conversation has a beat. Cross-linguistic studies put the gap between turns at roughly 100ms, with most languages clustering between 0 and 300ms (Stivers et al, PNAS 2009). Your ear has been tuning itself to that rhythm since you could speak.
For voice agents, anything under 500ms still feels like talking to a human. Past 800ms the wheels start coming off. Past one second, the caller wonders if the line dropped. Past three seconds, they have hung up.
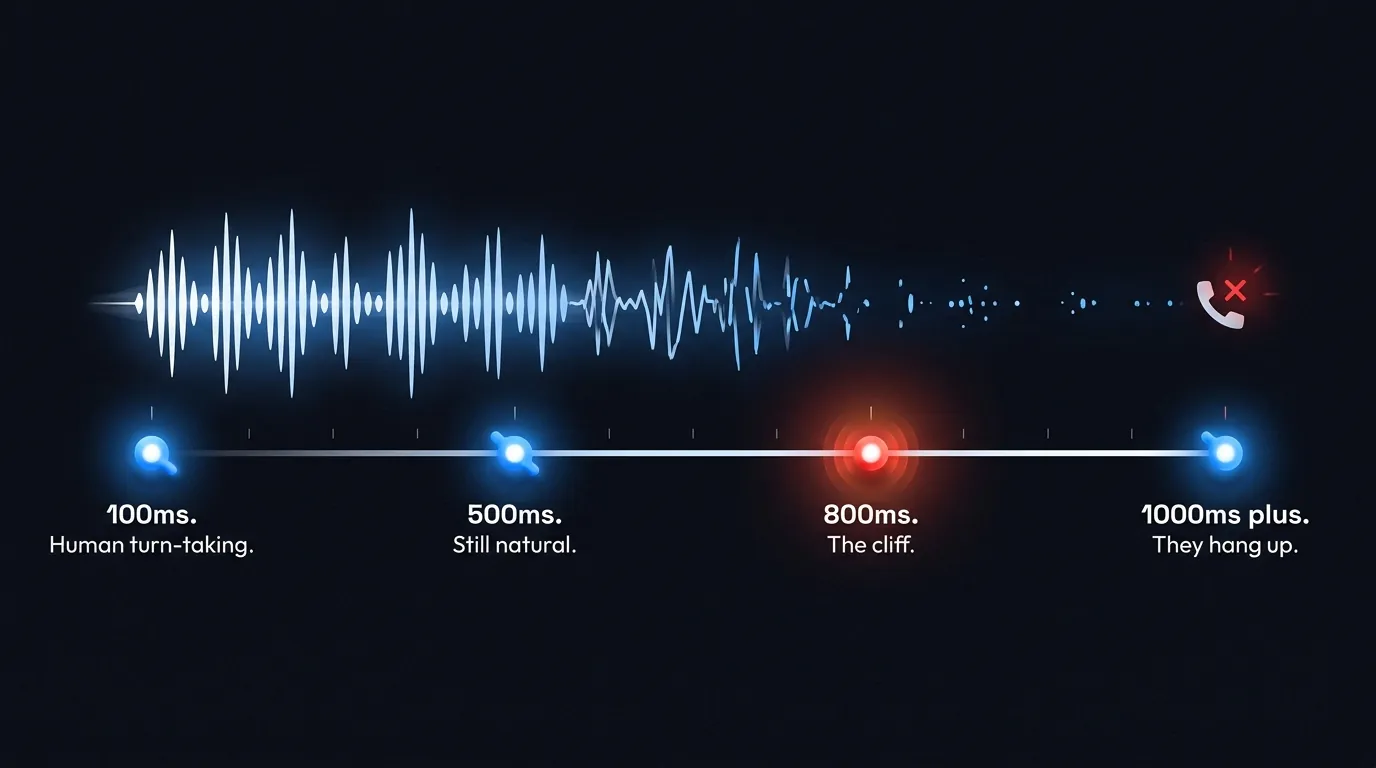
ElevenLabs Flash v2.5 ships first audio at roughly 75ms. Fast enough to live underneath the rest of your stack (speech-to-text, model thinking, tool calling) and still leave room before the cliff.
v3 has not published a number. Reviewers describe it as not real-time. Architecturally it is a larger model with a higher-fidelity codec. Both of those trade speed for sound.
Which is why ElevenLabs themselves list Flash v2.5, Flash v2, or Multilingual v2 as the recommended models for the Agents Platform. v3 is not on that list.
If your agent already feels slow, the voice model is rarely the only thing to look at. We wrote the full teardown on where voice agent latency actually hides.
Where v3 Wins
Where v3 actually wins
Pull v3 out of the live-call use case and it is genuinely impressive. Anything rendered once and played many times sits in its lane.
The trick is inline audio tags. Drop [laughs], [whispering], [sarcastic], [curious], or [breathy] inside the script and v3 performs them. Reviewers describe the output as indistinguishable from real speech in tone and flow.
It also handles multi-speaker dialogue (unlimited speakers in one render) and 70+ languages, covering roughly 90% of the global population. The numbers and symbols accuracy is 68% better than the alpha that landed in June 2025.

The use cases v3 was built for, in plain English:
- →Audiobooks and long-form narration. Performance carries the listener for hours. v3 holds it.
- →Film, TV and game dubbing. Multi-speaker mode plus 70+ languages.
- →Podcast generation and character work. Two voices in one render.
- →Marketing voiceovers and brand spots. Render once, run on every platform.
- →IVR prompts pre-rendered overnight. Greeting, on-hold copy, closure messages, voicemail. Generate them in v3, ship them as static files.
- →Training content and accessibility (AAC). Anywhere a human listens to the same line many times.
Where Flash Wins
Where Flash v2.5 wins
Anything live. The list is short and obvious.
- →Outbound sales agents. Cold calls, vendor outreach, arrears chase.
- →Inbound support agents. Reception, triage, after-hours cover.
- →IVR prompts generated on the fly. The ones that quote your caller's appointment time back at them.
- →Anything where the caller is on the line right now and the agent has to respond.
For those jobs, the fact that v3 sounds slightly warmer in a side-by-side does not matter. The 800ms beat is the gate. Cross it and the conversation breaks.
A useful rule of thumb: if you can render the audio file the night before, use v3. If the script is composed at speaking time, use Flash v2.5.
75ms first audio
That is the number Flash v2.5 ships at, and that is why ElevenLabs themselves told developers to use it instead of v3 on live agents. Quality in the wrong dimension costs you the call.
Voice Library
Same voice, different engine
The wrinkle that surprises people: voice IDs work on both engines. The "model" is the rendering engine. The voice ID is the speaker identity.
In practice, that means a single curated voice (a polished NZ presenter, an Australian inside-sales voice, a UK call agent) can be used at the studio engine for hold music and a campaign launch video, and at the call-floor engine for the actual outbound prospecting. Same person. Same character. Different engine for different work.
The voice is your brand. The engine is your job. Pick the engine for the job.
Hear it in action
40 curated voices, all running on the ElevenLabs stack
Pick a region. Hit play. Each one works under v3 (pre-recorded marketing) and Flash v2.5 (live calls).

Luke
New ZealandClear New Zealand accent, deep and steady. Great for professional customer service.

Harry
New ZealandSoft-spoken and warm Kiwi voice, perfect for friendly conversations.

Sam
New ZealandPlayful and warm Kiwi voice, great for friendly customer conversations.

Kim
New ZealandFriendly and descriptive Kiwi voice, perfect for informative calls.

Melissa
New ZealandCalm and steady Kiwi narrator, ideal for professional communications.

Torey
New ZealandConfident Kiwi voice with natural conversational flow.

Jessie
New ZealandFriendly educator voice, warm and encouraging Kiwi accent.

Arnold
New ZealandYouthful, friendly and light. Casual middle-aged Kiwi voice that lands well on everyday conversation.

Liam
New ZealandMeditative, captivating and wise. Calm Kiwi narrator with measured pacing, perfect for healthcare and professional services.

Tony
New ZealandWarm resonance and calm authority. Mid-40s Kiwi audiobook narrator voice, ideal for considered conversations and longer calls.

Paul
New ZealandSocial, outgoing and kind. Conversational middle-aged Kiwi who keeps the rapport up. Great for vendor follow-ups and warm callbacks.

Jane
New ZealandFirm and clear with a soft Kiwi accent. Authoritative middle-aged voice with crisp pronunciation, built for compliance-heavy calls.

Jenna
New ZealandClear, engaging and warm. Younger Kiwi female voice that sounds genuine on first-contact calls.

Cassandra
New ZealandCinematic, emotionally intelligent storyteller from Aotearoa. Bold middle-aged Kiwi voice for brand work and standout calls.
Want the full library? See all 40 voices on the voices page.
The Catches
The tradeoffs of v3 nobody warns you about
v3 is genuinely good. It is also genuinely fragile. Six things will bite you if you run it without care.
| Catch | What it means |
|---|---|
| Voice mismatch | If the underlying voice was recorded calm and you tag it [shouting], v3 often won't deliver. The base voice has to sit close to the target emotion or the tag goes ignored. |
| Stacking artefacts | Stack too many [break] tags and the output speeds up, garbles, or reads the tag aloud. One or two breaks per paragraph is the sane limit. |
| Library inconsistency | Voices from the public Voice Library produce less consistent v3 output than they did under v2.5 or v2. Tighter prompts and a base voice closer to your target tone help. |
| Premium pricing | On Retell, ElevenLabs TTS sits at $0.04 per minute after the March 2026 reset. Retell Platform Voices, Minimax, Fish Audio, Cartesia and OpenAI all start at $0.015. v3 is the higher tier. |
| 5,000 character cap | Per generation. Long monologues need chunking. Flash v2.5 takes 40,000 in one shot. |
| Prompt sensitivity | v3 cares more about how you structure your writing. Natural sentences, emotional context, performable phrasing. Tight rigid script gets you mediocre output. |
None of these kill v3. They just mean you have to use it for the work it was designed for.
The Decision
How to pick
Two questions. Answer them and the engine picks itself.
One. Is the audio rendered or live?
Rendered? v3.
Live? Flash v2.5.
Two. Is the script composed by your team or by the model in the moment?
Composed by your team and polished before the listener hears it? v3.
Composed by the model from caller context, on the line, right now? Flash v2.5.
That is the decision. Benchmarks do not take phone calls.
Want to hear properly picked voice tech on a live call?
Hear our voice agents on a real outbound or inbound flow. We pick the engine for the job, every time.
Frequently asked questions
What is ElevenLabs v3?
ElevenLabs v3 is the most expressive text-to-speech model in the ElevenLabs lineup, generally available since 2 February 2026 after an alpha that opened in June 2025. It supports 70+ languages, multi-speaker dialogue, and inline audio tags like [laughs], [whispering], and [sarcastic] that the model performs as part of the read. It is not a real-time model.
Can I use ElevenLabs v3 for voice agents?
ElevenLabs themselves recommend Flash v2.5, Flash v2, or Multilingual v2 for their Agents Platform. v3 is excluded because of its higher first-token latency. For pre-rendered IVR prompts, audiobooks, marketing voiceovers, and any audio rendered once and played many times, v3 is excellent. For live calls, Flash v2.5 is the right model.
What is the latency of ElevenLabs Flash v2.5?
Flash v2.5 ships first audio at approximately 75ms. That sits well inside the 500ms natural-conversation budget and well under the 800ms threshold beyond which a phone caller starts to feel the silence.
Does using v3 mean I have to change my voice?
No. Voice IDs are independent of the rendering model. The same voice you use under Flash v2.5 for live calls can also be rendered through v3 for marketing voiceovers and pre-recorded IVR. The voice is the speaker. The model is the engine.
How much does ElevenLabs v3 cost on Retell?
After the 23 March 2026 pricing reset, ElevenLabs TTS (which includes v3) sits at $0.04 per minute on Retell. Retell Platform Voices, Minimax, Fish Audio, Cartesia and OpenAI all start at $0.015 per minute. v3 is the premium tier, not the default.
When should I not use v3?
Anywhere the script is composed at speaking time and a human is waiting on the line. Outbound sales agents. Inbound support. On-the-fly IVR. Anywhere the 800ms beat matters.
What is the difference between ElevenLabs v3 and ElevenLabs Agents?
They are different products. v3 is a text-to-speech model. ElevenLabs Agents (sometimes called ElevenAgents) is a real-time voice agent platform with its own low-latency stack, interruption detection and action triggering. The Agents Platform uses Flash v2.5 by default, not v3. When you read about "ElevenLabs voice agents", check which one the article is talking about.
Leonardo Garcia-Curtis
Founder & CEO at Waboom AI. Building voice AI agents that convert.
Ready to Build Your AI Voice Agent?
Let's discuss how Waboom AI can help automate your customer conversations.
Book a Free Demo